Three studies. Same answer.
Validated against 405,000 real Americans.
Tested three ways. Once against a personality inventory the model could have seen during training. Once against a political survey published after our training cutoff. Once head to head against asking the AI directly. The headline numbers are below. The full receipts follow if you want them.
Three different validations. Two land at 91% match. One shows where plain AI without personas falls apart. Full methodology, per-item breakdowns, and figures below.
First, a quick primer · how the tool works
1
Build the people
We generate synthetic personas from public population distributions: U.S. Census demographics for age, region, education and income, plus published personality and value profiles. Each persona has a complete, internally consistent identity.
2
Ask them like real respondents
When you put a message, a poll, or a script in front of them, each persona reacts in their own voice, shaped by their personality, their life context, and the local culture they live in. The same persona stays consistent across every question.
3
Verify against reality
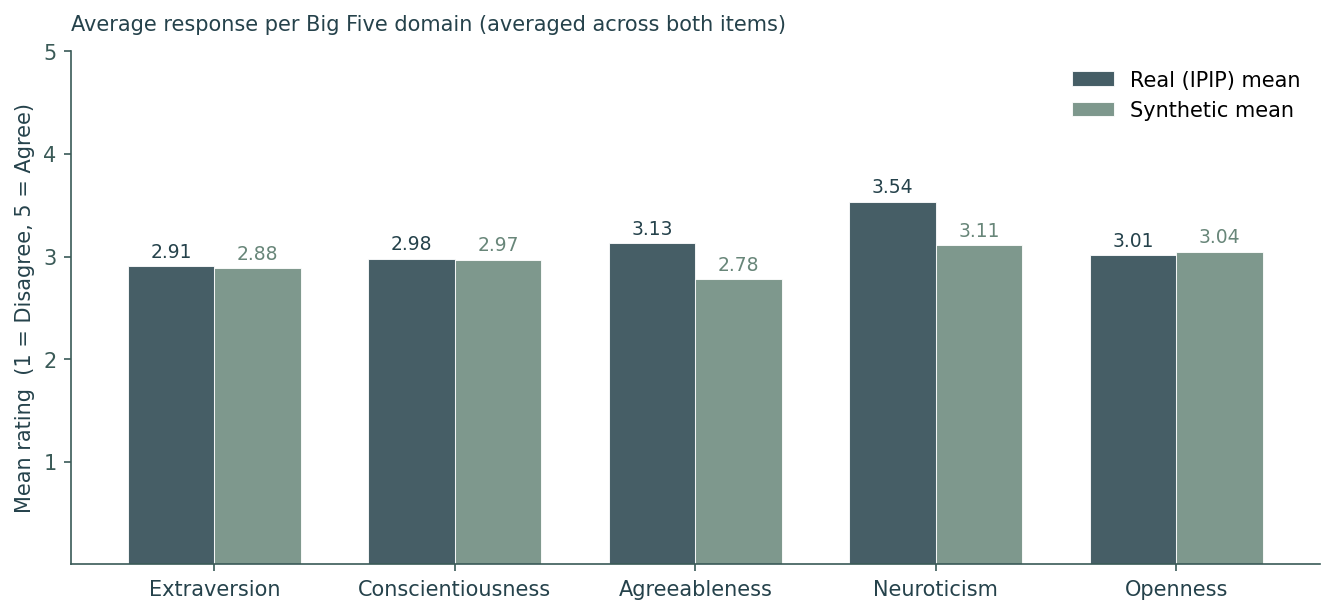
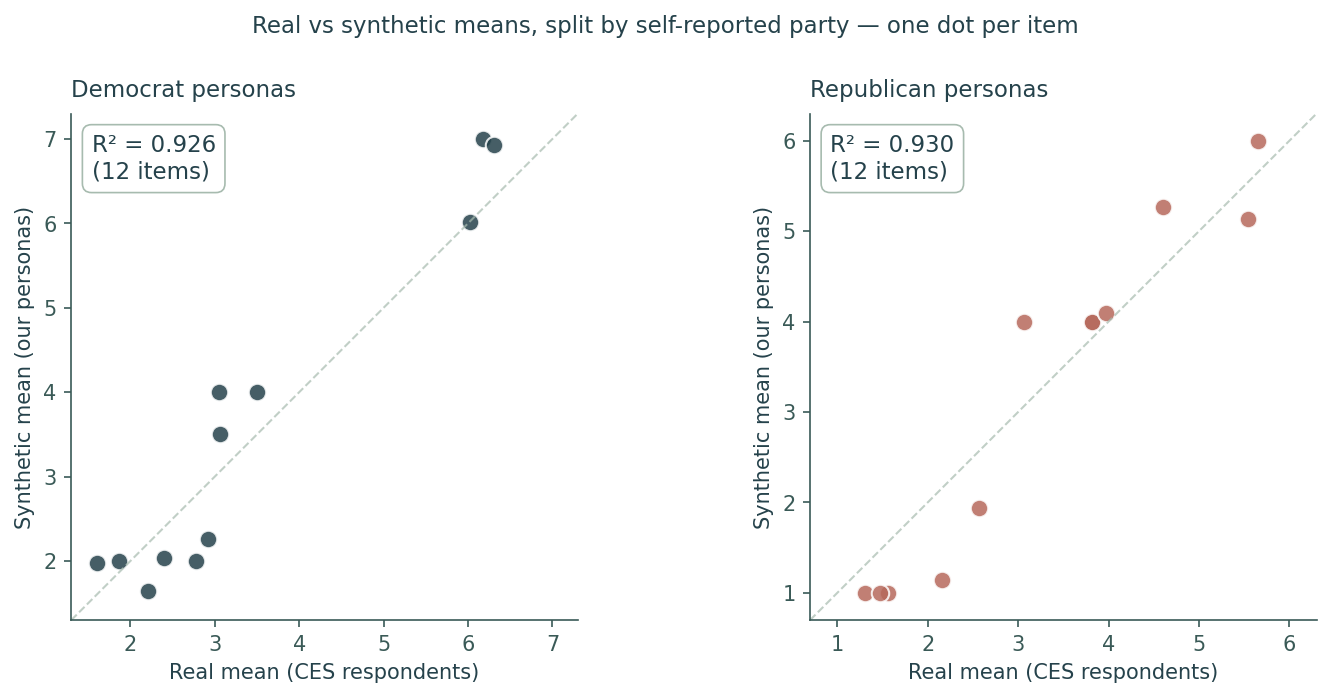
To make sure the personas actually behave like real humans, we run published surveys through them and compare the answer distributions to the real respondents. Below are two of those tests.
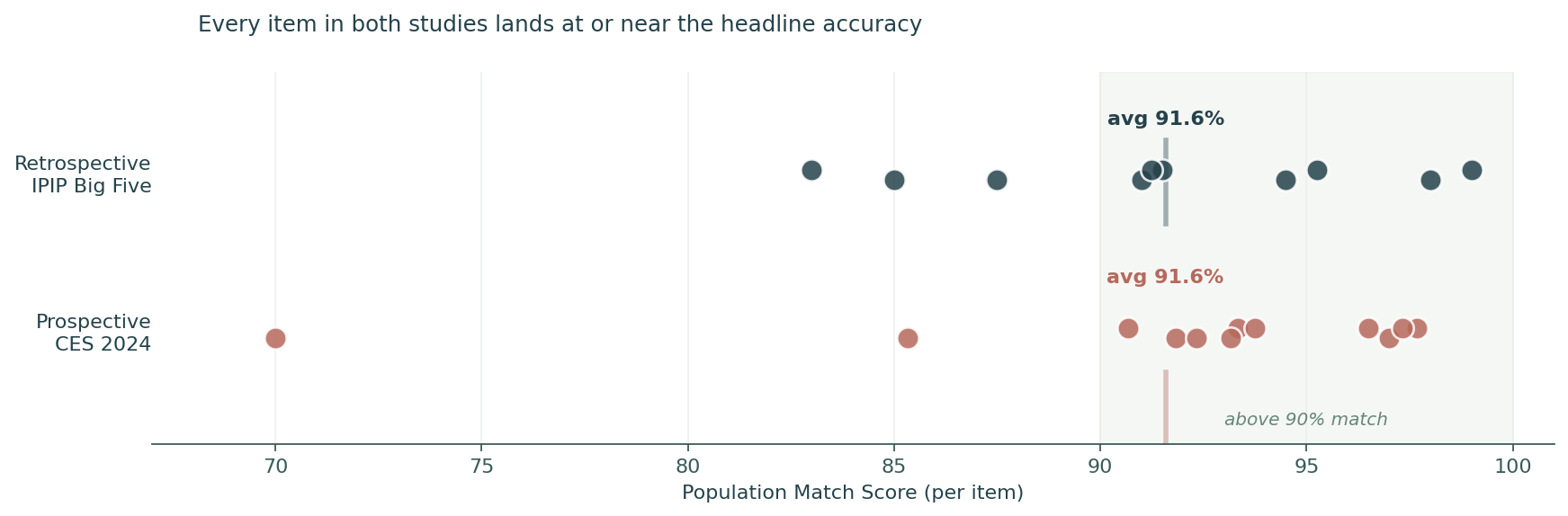
Headline · Population Match Score
Population Match Score = 100 × (1 − |synthetic mean − real mean| / scale range), averaged across items. A score of 100 means our synthetic personas' average answer is identical to real respondents'; 50 means our error is half the scale. We chose this metric over R² because it stays interpretable across rating scales (1-5 personality, 1-7 ideology, 0-100 thermometers) and answers a plain question: how close are we to real people, on the scale the researcher used?
Per-item breakdown
Every dot is one item. The shaded zone marks items above 90% match. The headline is not an average over wild swings. Both studies have their bulk of items clustered between 87% and 99% match, on the same scale, against completely different real-world populations.
What this means
Two independent validations on completely different real-world populations both land at roughly 91% Population Match Score. One study the model could have memorized. One it couldn't. Both measurements landed in the same band. That's evidence our personas model people, not memorized distributions. And on the questions where Americans actually disagree with each other, our personas hold structural accuracy that asking a chatbot directly cannot.
For the technically minded: the literal scores are 91.60% and 91.58%, within the sampling noise of either study at this size. The magnitude is the signal, not the third digit.
Synthetic people are a strong first signal. Pair with real-world research for high-stakes decisions. Methodology and per-item gaps are surfaced openly above. A copy of the validation report is available on request.